How it works
Process of transcribing audio
The process of transcribing is illustrated in the below figure
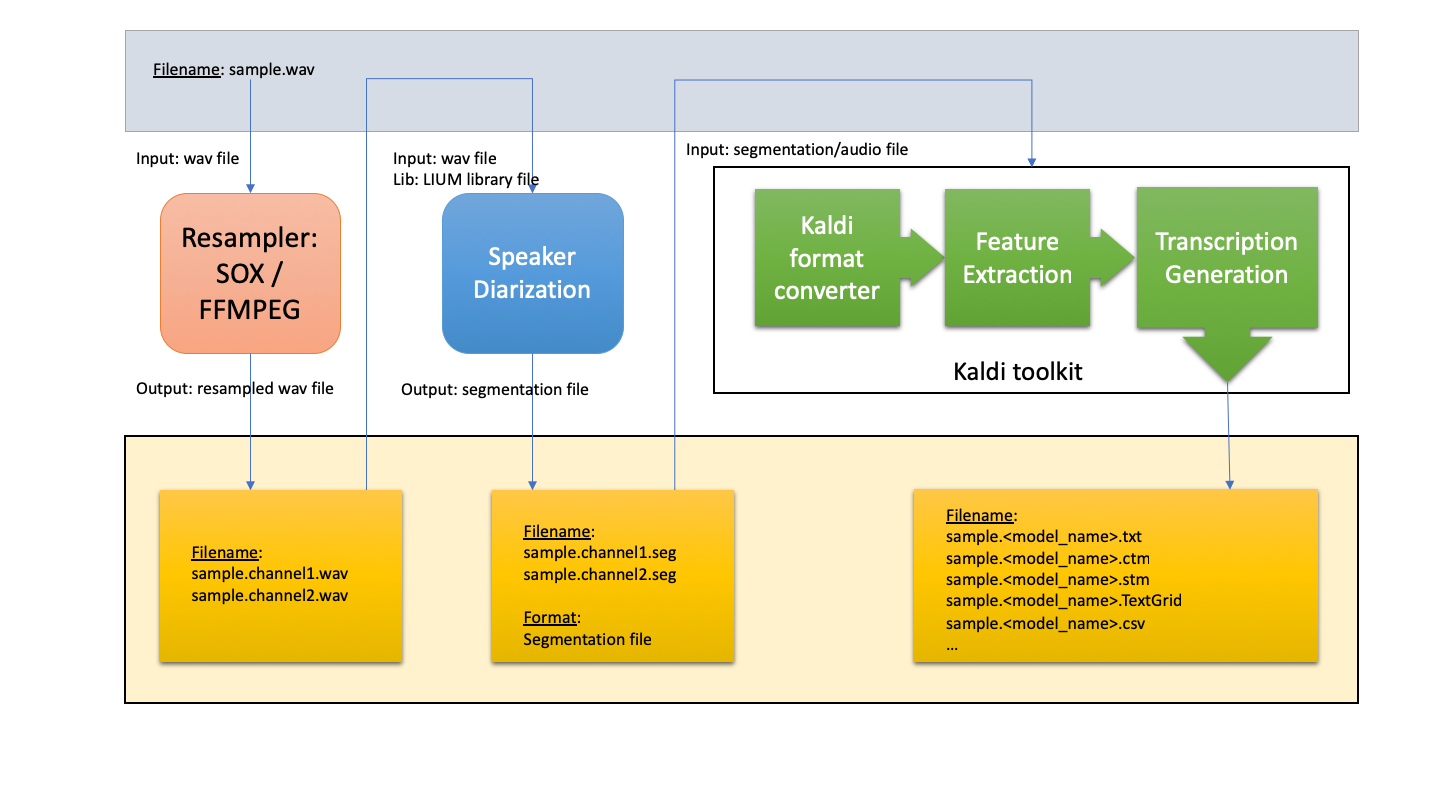
The above picture illustrates how the offline decoding system works. The audio input will be processed through steps
Step 1: Resample the audio file
The audio needs to be split into mono channels, and sample rate that match with the trained model.
Tools used: Soxi/ffmpeg
Step 2: Detect the speech in the input
Speaker diarisation (or diarization) is the process of partitioning an input audio stream into homogeneous segments according to the speaker identity.
Output of this process is the segment file (.seg), including the speaker id, segment that including speech, and start/end time
Step 3: Convert the audio to proper format
To process further by the decoding scripts, the audio data and segment file will be parse to appropriate format ready for the next step.
Step 4: Extract features from the input
Extract the features from the audio and speech segments
Step 5: Decode/Generate the transcription
Features extracted from previous step, with our trained model, to generate the transcription in ctm/stm format.
Furthermore, transcription are also converted to different formats, support different requests from user: like TextGrid, csv, text.
The file output will be sent to public folder, user could have other post-processing like converting to their required format, sending to other modules (language understanding, adding sentence unit, etc.)
The system will process input files sequentially. The ‘file_name’ of input audio files will be normalized into ‘file_id’. The output folder will have the following structure:
Information extraction from the output:
*.ctm file including word and start time, end time of each word.
*.srt, *.stm, *.textgrid including segments (sentences) with start time, end time.
*.txt including the whole transcription.
File type and language supported
Currently our offline system does support following file types and language models (list is not exhaustive):
Languages
Description
Singapore Code Switch
"Code-switching" between different languages such as English-Mandarin-Malay
Mandarin
Monolingual ASR model
Singapore English
English ASR model with localised terms
User can upload file with size up to 500MB each time
For all language models, we support the following file types: .wav, .mp3, .mp4, .flac, .ogg.
No matter what the input audio format, our offline system can process to down/up sample the audio file to the 16khz/8khz sampling rate, 16 bit rate, and mono channel to process. Our system performs best with audio in 16Khz sampling rate, 16 bit rate and close talk or telephony with clear and clean speech.
Last updated